Current State of AI in Pharma: Key Achievements Beyond Hype
/Last update -- 24 Dec 2019/
A background context -- opportunities and challenges
Current widespread interest towards artificial intelligence (AI) and its numerous research and commercial successes was largely catalyzed by several landmark breakthroughs in 2012, when researchers at the University of Toronto achieved unprecedented improvement in the image classification challenge ImageNet, using their deep neural network “AlexNet” running on graphics processing units (GPUs), and when that same year Google’s deep neural network managed to identify a cat from millions of unlabeled Youtube videos, representing a conceptual step in unsupervised machine learning.
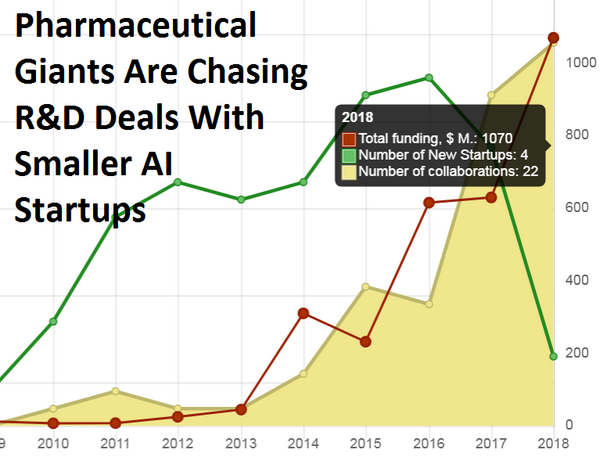
Nowadays, AI is commercially used in countless applications across various industries, ranging from surveillance, finance, marketing, automation, robotics, driverless cars etc. Pharmaceutical industry appeared to be a relative late adopter of AI tech, but the progress here is catching up rapidly now, for example, there were more research publications on the “AI for drug discovery” in 2018 alone, than in all previous years combined.
However, there is a major bottleneck in the application of deep learning (the current “workhorse” of modern AI) -- the need for large amounts of clean and properly linked data. The famous dataset ImageNet, which led to the AlexNet’s success, included 15 million labeled high-resolution images in over 22,000 categories, which represented a high-quality big data set. While in some cases obtaining clean data in large volumes is a manageable task, like in the case of speech recognition, in other cases data is scarce and disperse across multiple poorly linked sources -- which is the case in life sciences industry. Surprisingly, there is a tendency to overestimate the amount of available quality data in the pharmaceutical industry. Not only a lot of research data in drug development is in many cases poorly validated, but even properly validated data in a possession of numerous biopharma companies might not be easily available due to an inherent and strict code of secrecy, defined by severe competition among drug makers. In this situation, combining enough drug development data from multiple organizations and projects to really take advantage of AI/ML technologies on a global scale becomes a considerable challenge for the industry.
While the lack of quality data for training machine learning models might be, in some instances, overcome by state-of-the-art strategies, like transfer learning, synthetic data, or approaches to train on small data sets, the “prime-time” has not yet come for them in the pharmaceutical industry.
Another bottleneck -- validation of any findings offered by AI after performing analysis (especially, in unsupervised learning mode) on highly domain-specific and feature-rich datasets -- e.g. those derived from “omics” studies in biomedical research programs. If we talk about identifying cats in millions of unannotated videos -- that is fine, as we all know cats, and we can appreciate results right away. But when AI finds intricate data patterns or correlations in feature-rich biomedical data, it might not be obvious what we will be looking at. So far, AI can find both meaningful patterns, and nonsense patterns -- just as well.
This issue is reflected in an interview with Dr. Alex Zhavoronkov, one of the leading experts in the area of pharmaceutical AI: “When applying the deep learning techniques to images and videos validation is almost instantaneous and often you can see what to fix. This rapid pace of validation allowed for the driverless Tesla and for the deep-learned Google translate. But when dealing with molecules or biomarkers, it takes a very long time.”
Notwithstanding the above bottlenecks, AI is already delivering value in a wide range of pharmaceutical tasks, albeit not in all cases as rapidly as numerous media outlets tend to predict. Let’s review and assess some practical outputs achieved so far with the adoption of AI.
(For every use case, I assessed three parameters below, applying points from 1 to 5:
a) state-of-the-art capabilities of AI technology in a particular use case,
b) validation status in practice (public disclosures, FDA-approvals, user references etc), and
c) potential business impact of that particular use case on the pharmaceutical industry in general.
(Infographic design by Evgeniy Gumenyuk)
1. Mining data to build and visualize research ontologies
Continue reading
This content available exclusively for BPT Mebmers
We use cookies to personalise content and to analyse our traffic.
You consent to our cookies if you continue to use our website. Read more details in our
cookies policy.